Auguste and Louis Lumière were pioneers of filmmaking. Around the turn of the 20th century, the brothers developed the cinématographe, a device that could record, develop, and project motion pictures. It was one of the world’s first movie cameras. In 1895, they held the first screening of a motion picture with their short film Workers Leaving the Lumière Factory.
Now, in 2024, Google has released a preprint paper detailing the workings of Lumiere, the company’s new text-to-video AI model. Whether its namesake is history’s cinematic brothers or simply the French word for “light” — we choose to believe the former — it is clear that the company hopes this technology will be just as groundbreaking for the realm of digital video production as the Lumière’s cinématographe.
Developed in collaboration with researchers from the Weizmann Institute and Tel-Aviv University, Lumiere introduces a new architecture called “Space-Time U-Net.” According to the preprint’s authors, Lumiere not only creates state-of-the-art videos based on text prompts or still images. It will also bring video AI models closer to parity with their image-generating peers, such as DALL-E and Midjourney.
Bringing images to stylized life
Google’s demo reel shows Lumiere sporting a wide range of applications. Users simply provide a text prompt — such as “an aerial view of fireworks exploding in the night sky” — and Lumiere will output a 5-second, 1024×1024 video of just that. (The videos are 80 frames long at 16 frames per second, hence 5 seconds.)
Users can also provide a still image to serve as the foundation of a video and then give instructions for what should happen next. In Google’s demo, Lumiere was provided with a photo of Vermeer’s painting “Girl with a Pearl Earring” and the prompt “a girl winking and smiling.” The painting obliged.
The AI model also made the “Mona Lisa” yawn, Sir Isaac Newton wave, and the mask of Tutankhamun smile in lapis splendor.

In addition to video creation, the model can perform editorial tasks, such as video stylization, cinemagraphs, and video inpainting.
Stylization alters the, well, style of the image. You can take a realistic image of a woman running and make a video in which she’s made of origami. Another example shows a car being transformed into a life-sized LEGO kit. The model can also borrow the style of a reference image and create new media with it.
The cinemagraphs feature allows users to select something within an image, such as rippling water or a butterfly, and animate that specific content. Finally, video inpainting can be used to replace missing or obscured parts of the image frame.
Keyframes to success
None of these features are groundbreaking for text-to-video models; instead, it’s the model’s architecture that Google claims will prove revolutionary.
According to the preprint, most current text-to-video models first create separate images based on a prompt, like any other text-to-image AI. These images are called “keyframes” and they define the important positions of the video.
What does that mean? If the user prompt is, say, waves at the beach, then the keyframes might include the wave building, cresting, falling, and breaking against the sand. These models then estimate the motion necessary to blend the keyframes together and, using something called “temporal super-resolution,” generate images to fill in the gaps. When the keyframes and these images are strung together, it creates a sense of motion.
In many ways, this approach tries to replicate how traditional animators work. However, according to the preprint authors, certain limitations within text-to-video models often led to less-than-stellar results.
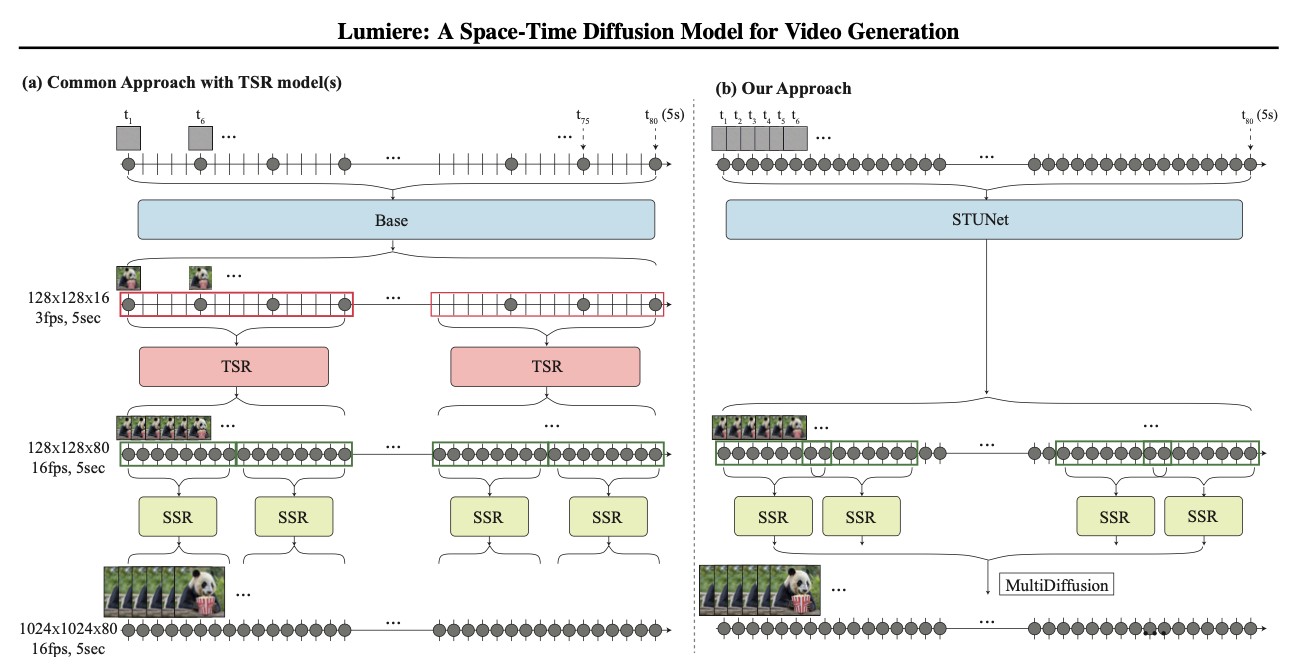
For instance, current models tend to “aggressively” reduce the number of keyframes for faster processing and lighter information loads. They also analyze a limited number of frames at a time. So while the model can ensure certain keyframes and their in-betweens flow together nicely, it doesn’t consider consistency across the whole video. All of which can add up to error-filled, ambiguous, hallucinogenic, and sometimes, frankly, even nightmarish results.
Lumiere is different. The model generates “the entire temporal duration of the video at once, through a single pass of the model.” In other words, it creates the entire video from start to finish in one fluid process. Rather than analyzing a limited number of frames piecemeal, it always considers where objects are in the frames (space) and how they move and change between them (time). In doing so, the resulting videos are smoother, more animated, and less prone to error.
“[The other models’] outputs are characterized by a very limited amount of motion, often resulting in near-static videos,” the authors write. “Our method was preferred over all baselines by [study participants] and demonstrated better alignment with the text prompts.”
Will Lumiere see the light?
Lumiere’s architecture was trained on a dataset of 30 million videos with text captions (though the authors don’t specify the source of these videos). It was then evaluated based on 113 prompts describing various objects and scenes — 18 of which came from the researchers and 95 from prior works.
The researchers asked roughly 400 participants to state their preferences between Lumiere’s video and those generated by other text-to-video AIs, such as Pika and Runway’s Gen-2.
With that said, here are some caveats. Google has not yet released Lumiere for outside testing. As a preprint, the paper has not undergone peer-review and the sample size of 113 is small. Google also has a history of somewhat exaggerated demos, and while some of the company’s homebrewed sample videos are truly impressive, others look like short documentaries shot in the uncanny valley. (Whatever is being poured onto that ice cream is not chocolate syrup.)
All of which is to say, until others can test the limits and abilities of the technology, take everything with a stylized, well-animated grain of salt.
However, if Lumiere can live up to its namesake, it may prove the breakthrough that brings text-to-video AIs from the primitive state to something more on par with other modern AI tools.





