

This article is an installment of Future Explored, a weekly guide to world-changing technology. You can get stories like this one straight to your inbox every Saturday morning by subscribing here.
It’s 2030, and artificial general intelligence (AGI) is finally here. In the years to come, we’ll use this powerful technology to cure diseases, accelerate discoveries, reduce poverty, and more. In one small way, our journey to AGI can be traced back to a $1 million contest that challenged the AI status quo back in 2024.
Artificial general intelligence
Artificial general intelligence (AGI) — software with human-level intelligence — could change the world, but no one seems to know how close we are to building it. Experts’ predictions range from 2029 to 2300 to never. Some insist AGI is already here.
To find out why it’s so hard to predict the arrival of AGI, let’s take a look at the history of AI, the ways we currently measure machine intelligence, and the $1 million competition that could help guide us to this world-changing software.
Where we’ve been

Where we’re going (maybe)
So, how will we know when AGI is going to arrive?
Benchmark tests are a useful way to track AI progress, and choosing them for AIs designed for just one task is generally pretty easy — if you’re training an AI to identify heart problems from echocardiograms, for example, your benchmark might be its accuracy compared to doctors.
But AGI is, by definition, supposed to possess general intelligence, the kind humans have. How do you benchmark for that?
For decades, many considered the Turing test a solid benchmark for AGI (even if that’s not exactly how Alan Turing intended it to be used). If an AI could convince a human evaluator that it was human, it was functionally exhibiting human-level intelligence, the thinking went.
But when a chatbot modeled after a teenager “passed” the Turing test in 2014 by, well, acting like a teenager — deflecting questions, cracking jokes, and basically acting sort of dumb — nothing about it felt particularly intelligent, let alone intelligent enough to change the world.

Since then, breakthroughs in large language models (LLMs) — AIs trained on huge datasets of text to predict human-like responses — have led to chatbots that can easily fool people into thinking they’re human, but those AIs don’t seem very intelligent, either, especially since what they say is often false.
With the Turing test deemed broken, “outdated,” and “far beyond obsolete,” AI developers needed new benchmarks for AGI, so they started having their models take the toughest tests we have for people, like the bar exam and the MCAT, and the MMLU, a benchmark created in 2020 specifically to evaluate language models’ knowledge on a range of subjects.
Now, developers regularly report how their newest AIs performed relative to human test takers, previous AI models, and their AI competitors, and publish their results in papers with titles such as “Sparks of Artificial General Intelligence.”

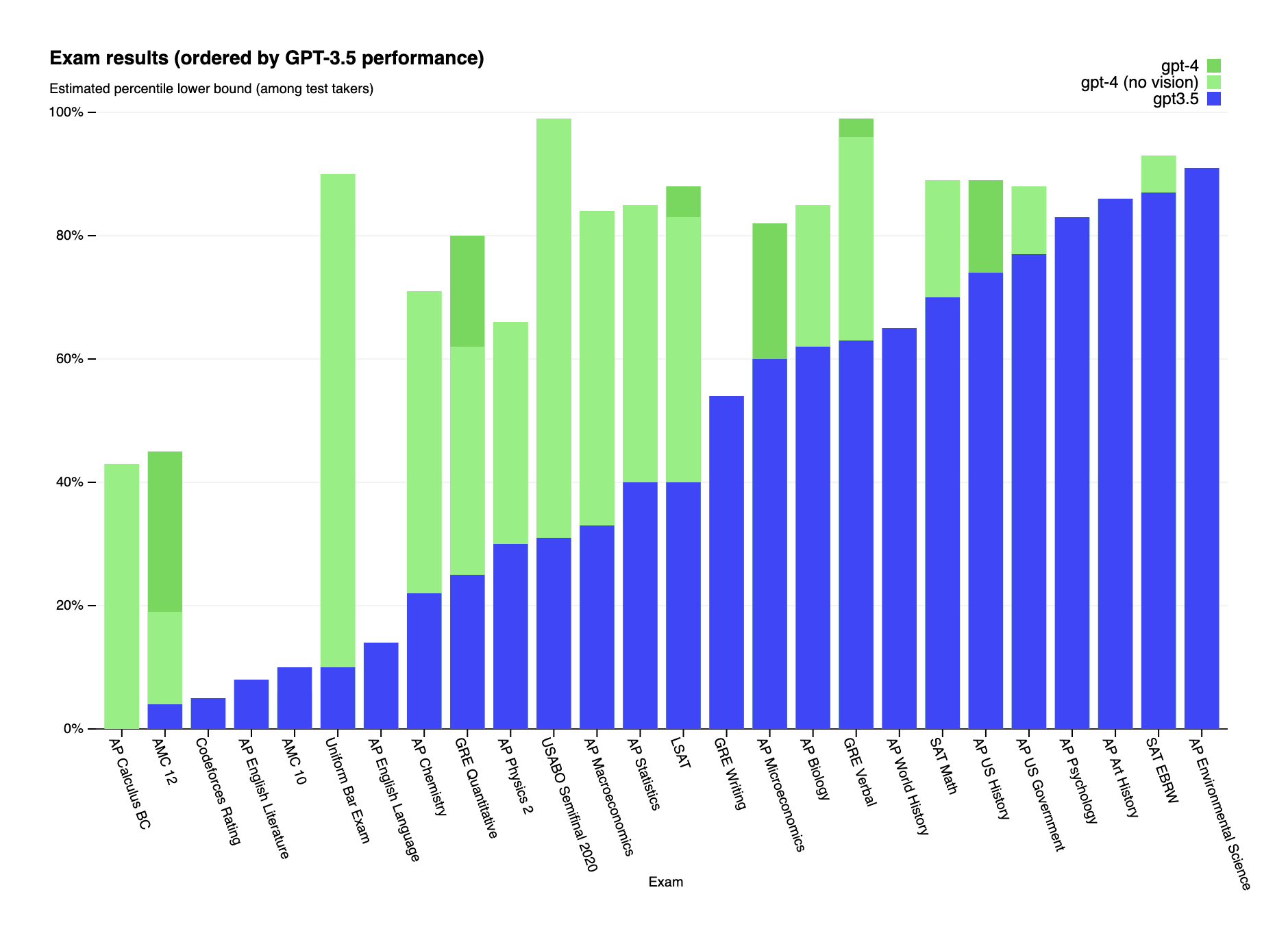
These benchmarks do give us a more objective way to evaluate and compare AIs than the Turing test, but despite the way they look, they aren’t necessarily showing progress toward AGI, either.
LLMs are trained on massive troves of text, mostly pulled from the internet, so it’s likely that many of the exact same questions being used to evaluate a model were included in its training data — at best, tipping the scales and, at worst, allowing it to simply regurgitate answers rather than perform any sort of human-like reasoning.
And because AI developers typically don’t release details on their training data, those outside the companies — the people trying to prepare for the (maybe) imminent arrival of AGI — don’t really know for certain whether this issue, known as “data contamination,” is affecting test results.
“Memorization is useful, but intelligence is something else.”
François Chollet
It sure seems to be, though. In testing, researchers have found that a model’s performance on these benchmarks can fall dramatically when it is challenged with slightly reworded test problems or ones that have been created entirely after the cutoff date for its training data.
“Almost all current AI benchmarks can be solved purely via memorization,” François Chollet, a software engineer and AI researcher, told Freethink. “You can simply look at what kind of questions are in the benchmark, then make sure that these questions, or very similar ones, are featured in the training data of your model.”
“Memorization is useful, but intelligence is something else,” he added. “In the words of Jean Piaget, intelligence is what you use when you don’t know what to do. It’s how you learn in the face of new circumstances, how you adapt and improvise, how you pick up new skills.”
“It’s designed to be resistant to memorization. And so far, it has stood the test of time.”
François Chollet
In 2019, Chollet published a paper in which he describes a deceptively simple benchmark for evaluating AIs for this kind of intelligence: the Abstraction and Reasoning Corpus (ARC).
“It’s a test of skill-acquisition efficiency, where every task is intended to be novel to the test-taker,” said Chollet. “It’s designed to be resistant to memorization. And so far, it has stood the test of time.”
ARC is similar to a human IQ test invented in 1938, called Raven’s Progressive Matrices. Each question features pairs of grids, ranging in size from 1×1 to 30×30. Each pair has an input grid and an output grid, with cells in the grids filled in with up to 10 different colors.
The AI’s job is to predict what the output should look like for a given input, based on a pattern established by one or two examples.

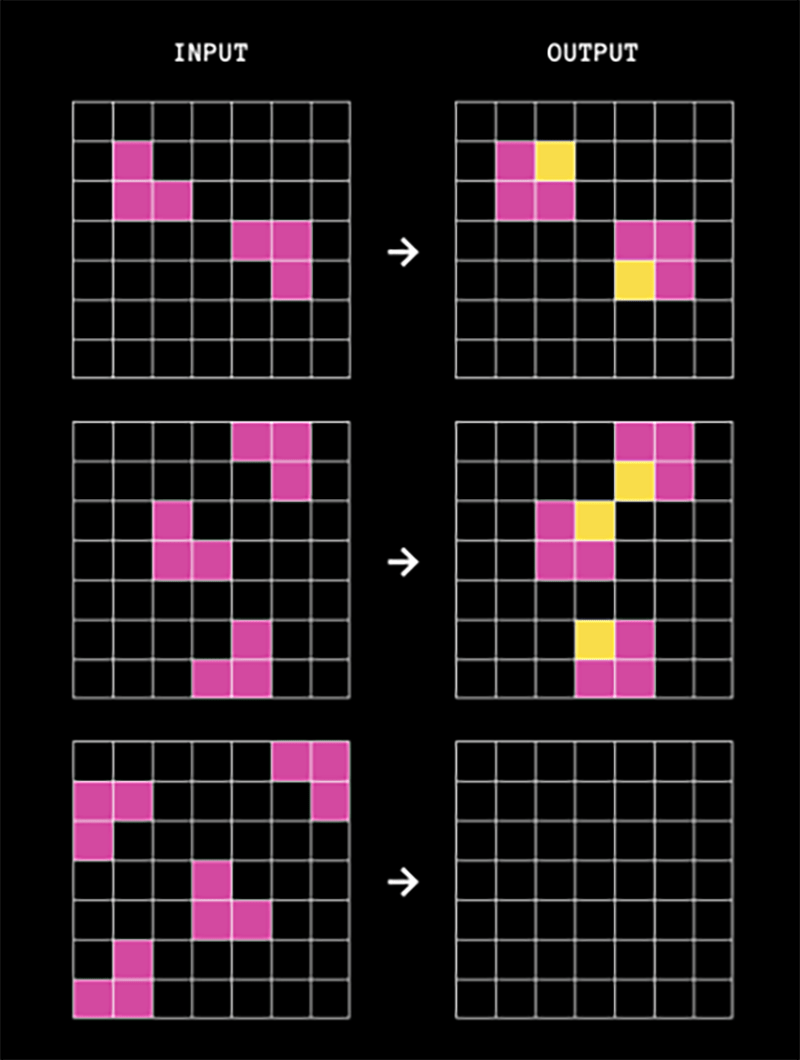
Since publishing his paper, Chollet has hosted several ARC competitions involving hundreds of AI developers from more than 65 nations. Initially, their best AIs could solve 20% of ARC tasks. By June 2024, that had increased to 34%, which is still far short of the 84% most humans can solve.
To accelerate progress in AI reasoning, Chollet teamed up with Mike Knoop, co-founder of workflow automation company Zapier, in June to launch ARC Prize, a competition to see which AIs can score highest on a set of ARC tasks, with more than $1 million (and a lot of prestige) up for grabs for the best systems.

Public training and evaluation sets for the competition, each consisting of 400 ARC tasks, are available to developers on GitHub. Entrants must submit their code by November 10, 2024, to compete.
The AIs will then be tested on ARC Prize’s private evaluation set of 100 tasks offline — this approach ensures test questions won’t get leaked and AIs won’t get a chance to see them before the evaluation.
Winners will be announced on December 3, 2024, with the five highest scoring AIs each receiving between $5,000 and $25,000 (at the time of writing, one team has managed 43%). To win the grand prize of $500,000, an entrant’s AI must solve 85% of the tasks. If no one wins, that prize money will roll over to a 2025 competition.
To be eligible for any prizes, developers must be willing to open source their code.
“The purpose of ARC Prize is to redirect more AI research focus toward architectures that might lead toward artificial general intelligence (AGI) and ensure that notable breakthroughs do not remain a trade secret at a big corporate AI lab,” according to the competition’s website.
“OpenAI basically set back progress to AGI by five to 10 years.”
François Chollet
This new direction could likely be away from LLMs and similar generative AIs. They raked in nearly half of AI funding in 2023, but — according to Chollet — are not only unlikely to lead to AGI, but are actively slowing progress toward it.
“OpenAI basically set back progress to AGI by five to 10 years,” he told the Dwarkesh Podcast. “They caused this complete closing down of frontier research publishing, and now LLMs have essentially sucked the oxygen out of the room — everyone is doing LLMs.”
He’s not alone in his skepticism that LLMs are getting us any closer to AGI.
Yann LeCun, Meta’s chief AI scientist, told the Next Web that “on the path towards human-level intelligence, an LLM is basically an off-ramp, a distraction, a dead end,” and OpenAI’s own CEO Sam Altman has said he doesn’t think scaling up LLMs will lead to AGI.

As for what kind of AI is most likely to lead to AGI, it’s too soon to say, but Chollet has shared details on the approaches that have performed best at ARC so far, including active inference, DSL program synthesis, and discrete program search. He also believes deep learning models could be worth exploring and encourages entrants to try novel approaches.
Ultimately, if he and others are right that LLMs are a dead end on the path to AGI, a new test that can actually identify “sparks” of general intelligence in AI could be hugely valuable, helping the industry shift focus to researching the kinds of models that will lead to AGI as soon as possible — and all the world-changing benefits that could come along with it.
Update, 8/5/24, 6:30 pm ET: This article was updated to include the latest high score on the ARC-AGI benchmark and to specify that 34% was the highest score as of June 2024.
We’d love to hear from you! If you have a comment about this article or if you have a tip for a future Freethink story, please email us at tips@freethink.com.







